G100
version 7.1
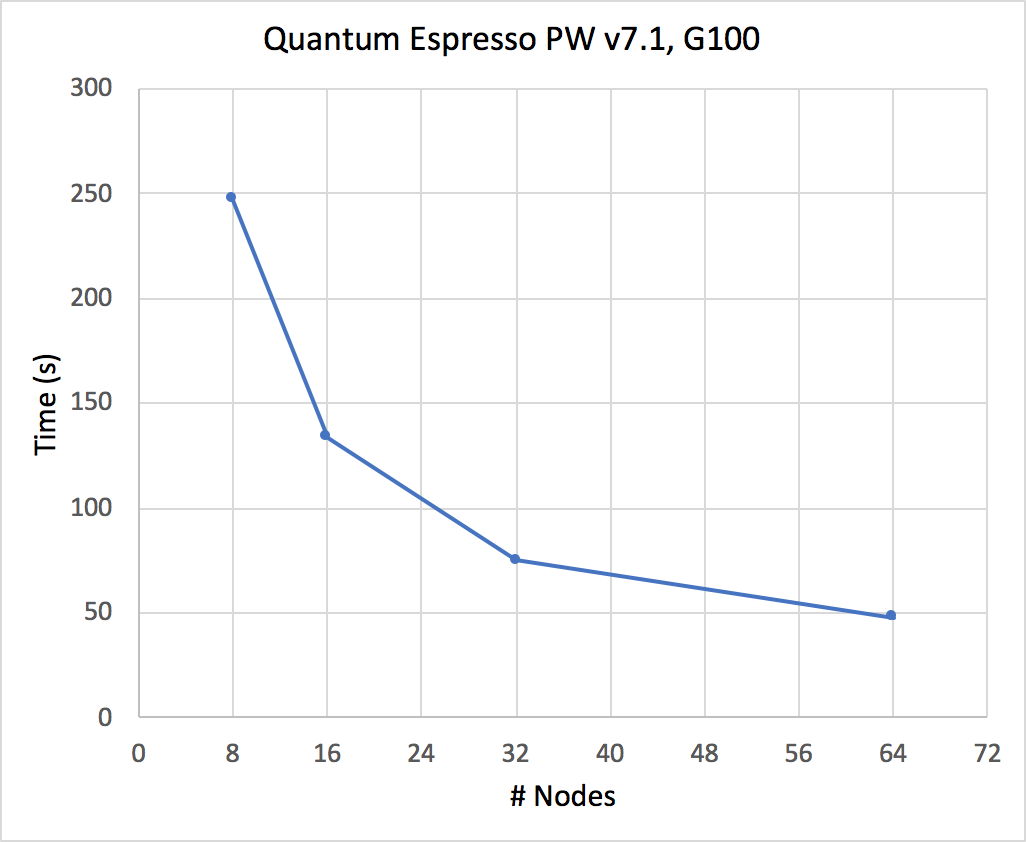
CNT10POR8 : R&G scaling on the CPU
- Performance analysis for a a Carbon nanotube functionalized with two porphyrine molecules, about 1500 atoms, 8000 bands, 1 k-point
- The average time per iteration is reported as a function of the number of nodes.
N° nodes | Time (s) |
| 8 | 248 |
| 16 | 134 |
| 32 | 75 |
| 64 | 48 |
Graphic 1: the QE performance (simulation time in s) is reported vs. the increasing number of nodes
Leonardo
version 7.2
CNT10POR8 : R&G scaling on the GPUs
- Performance analysis for a a Carbon nanotube functionalized with two porphyrine molecules, about 1500 atoms, 8000 bands, 1 k-point.
- The average time per iteration is reported as a function of the number of nodes.
Table2: The performance of the MPI (1 task per GPU) + GPU (4 per node) + OpenMP (8 threads per task)
N° nodes | Time (s) |
| 8 | 21.34 |
| 16 | 14.06 |
| 20 | 12.18 |
| 24 | 11.60 |
Graphic 2: the QE(v7.2) performance (simulation time in s) is reported vs. the increasing number of nodes
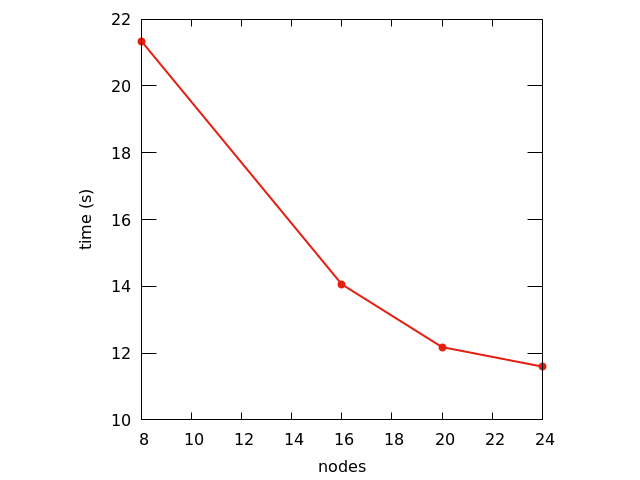
GPUs strongly improve the time to solution, but scaling with R&G has little efficiency beyond the minimum number of GPUs to be used for memory constraints.
Si-16layers: Pool scaling
- Performance analysis of the linear response calculation in ph.x for the system benchmarked here https://gitlab.hpc.cineca.it/cineca-benchmarking/applications/-/blob/main/quantum_espresso/Leonardo/small/SI16L-workflow-irr1/plot.png.
- Scaling with increasing pools ( one pool per gpu ) for a single irreducible representation
{kind=link}
# Nodes Pools Threads/Task phqscf ortho sth_kernel h_psi walltime (s)
#-----------------------------------------------------------------------------
1 1 8 2136.07 121.23 2047.89 1020.39 2203.88
1 2 8 1099.34 64.39 1047.00 510.10 1137.37
1 4 8 578.17 36.58 536.48 255.31 602.50
2 8 8 302.31 18.34 272.62 128.10 318.61
4 16 8 161.82 9.68 138.19 64.21 174.65
8 32 8 91.60 4.94 70.84 32.48 102.50
16 64 8 55.81 2.66 36.04 16.10 66.44
Graphic 3: the QE performance (simulation time in s) is reported vs. the increasing number of nodes with different speedups
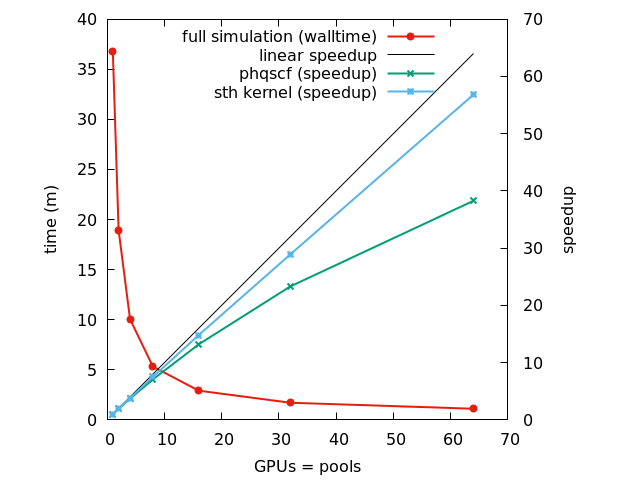
Pools scale efficiently on GPUs (this is true also for pw.x)
© Copyright 2