Package: Quantum-ESPRESSO
G100
version 7.1
CNT10POR8 : R&G scaling on the CPU
- Performance analysis for a a Carbon nanotube functionalized with two porphyrine molecules, about 1500 atoms, 8000 bands, 1 k-point
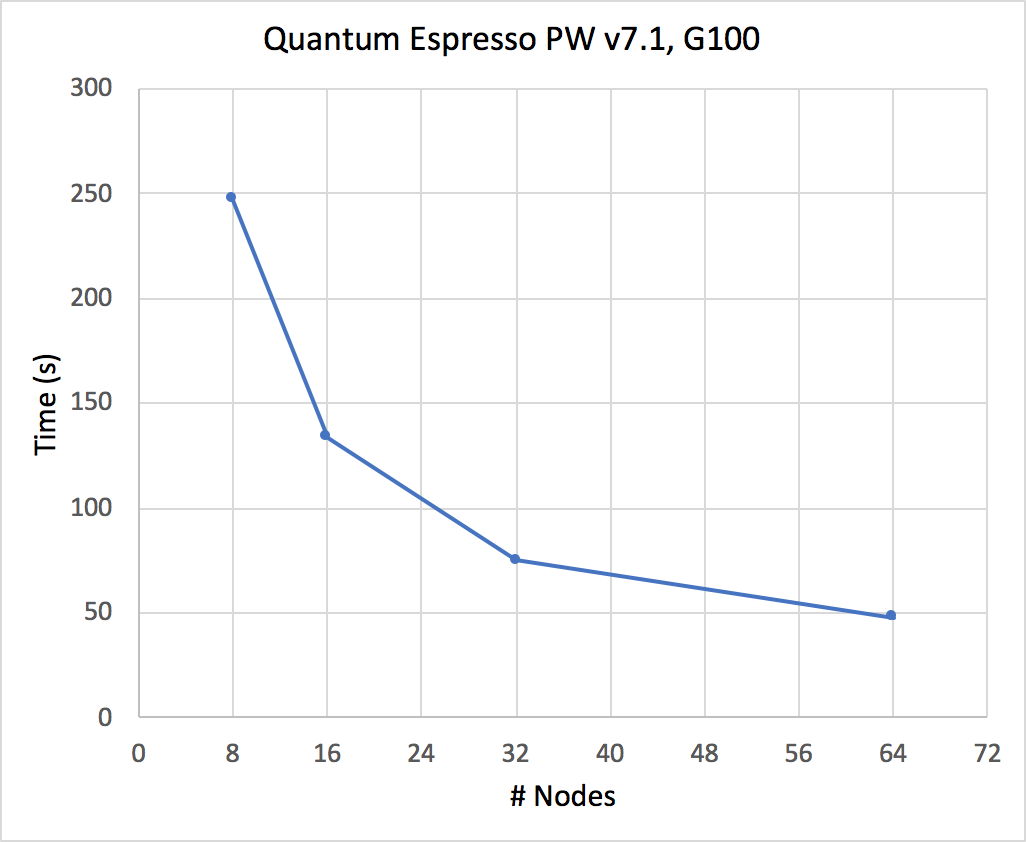
- The average time per iteration is reported as a function of the number of nodes.
Table1: The performance of the Pure MPI
N° nodes | Time (s) |
| 8 | 248 |
| 16 | 134 |
| 32 | 75 |
| 64 | 48 |
Graphic 1: the QE performance (simulation time in s) is reported vs. the increasing number of nodes
Leonardo
version 7.2
CNT10POR8 : R&G scaling on the GPUs
- Performance analysis for a a Carbon nanotube functionalized with two porphyrine molecules, about 1500 atoms, 8000 bands, 1 k-point.
- The average time per iteration is reported as a function of the number of nodes.
Table2: The performance of the MPI (1 task per GPU) + GPU (4 per node) + OpenMP (8 threads per task)
N° nodes | Time (s) |
| 8 | 21.34 |
| 16 | 14.06 |
| 20 | 12.18 |
| 24 | 11.60 |
Graphic 2: the QE(v7.2) performance (simulation time in s) is reported vs. the increasing number of nodes

GPUs strongly improve the time to solution, but scaling with R&G has little efficiency beyond the minimum number of GPUs to be used for memory constraints.
© Copyright 2