Scopo della reportistica è produrre report, liste, conteggi, indici.
Questi risultati sono personalizzabili attraverso:
-filtri di ricerca
-campi estraibili
-formato di esportazione.
La selezione dei campi da visualizzare e/o esportare avviene mediante la selezione delle colonne da estrarre, come mostrato nella figura seguente:
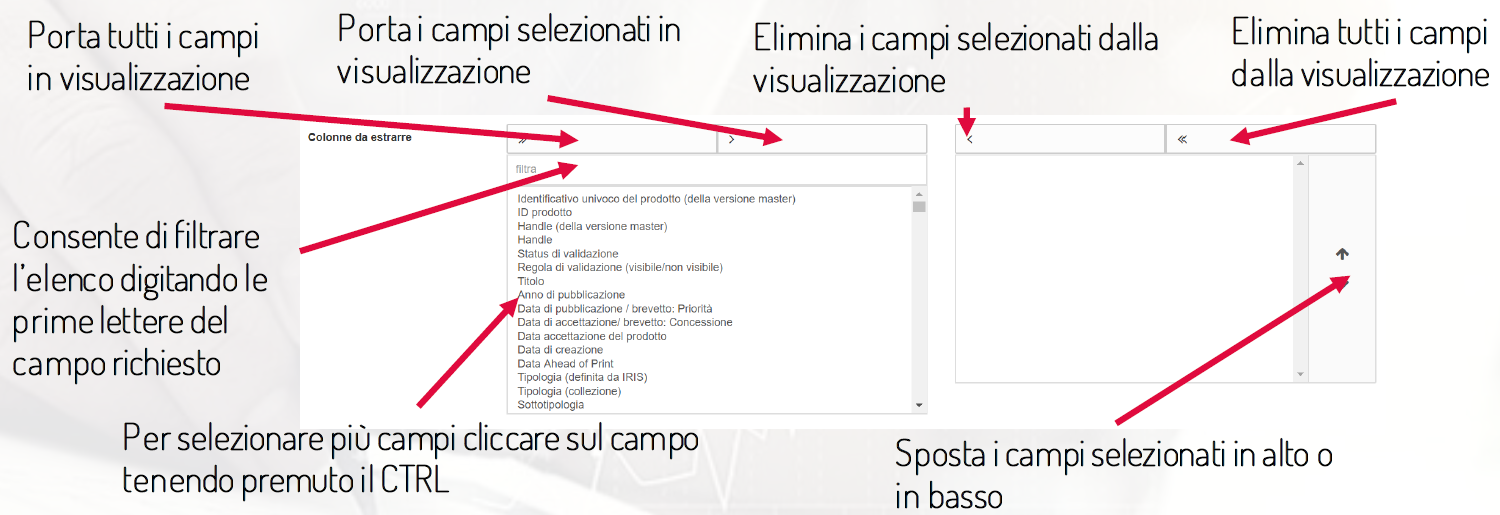
Filtri chiave: la tipologia di metadati da estrarre viene indicata nel primo filtro a tendina.
Se non si altera la selezione della tendina, di default si scelgono i dati MISTI, il cui significato è chiarito nella figura seguente.
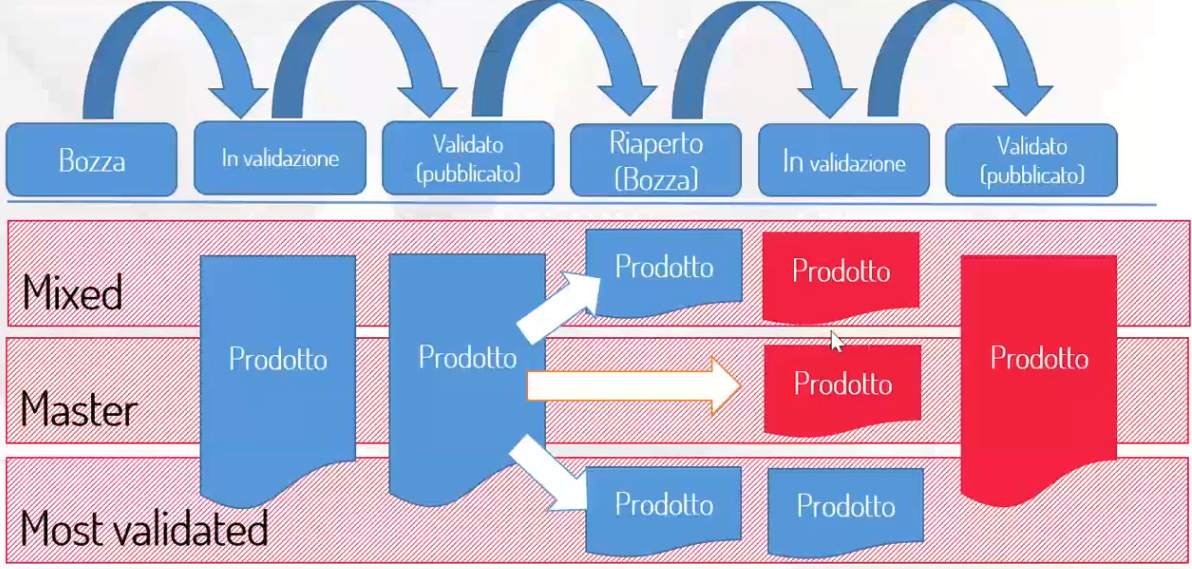
Infatti, nel ciclo di vita di un item all’interno del sistema IRIS, possono esistere più versioni della medesima pubblicazione.
Bozza → in validazione → validato (pubblicato) → riaperto (ancora bozza) → in validazione → validato
Si ricordi che i dati in reportistica sono delle COPIE, non sono i dati stessi.
Nel caso dello stato “bozza”, il prodotto non viene considerato in ER-Reportistica.
Quando invece passa nello stato “in validazione”, allora passa in Reportistica e analisi. Se però il prodotto viene riaperto, si possono avere situazioni diverse.
Versione MASTER: la più aggiornata.
Versione MOST VALIDATED: la più validata.
In funzione di cosa si intende fare con i dati della reportistica, si può essere interessati ai dati più freschi e aggiornati o a quelli più validati. Nel caso di una campagna di valutazione, ad esempio, non si vogliono considerare i dati corretti all’ultimo momento e non validati dagli uffici ricerca. Viceversa, se si sta facendo una campagna interna di pulizia dell’archivio, i ricercatori stanno lavorando per aggiornare i loro prodotti e quindi siamo interessati a quelli riaperti e modificati.
La versione MASTER esclude i casi di riapertura. Se i prodotti fossero 100 e uno di questi fosse riaperto, saranno visibili solo 99 prodotti, qualora venissero estratti i dati master in reportistica. Finché non è sottoposto alla validazione, anche il prodotto storico scompare perché master significa solo dati CONSOLIDATI. Un prodotto "respinto" durante la validazione subisce la stessa sorte, non viene cioè più considerato fra i dati master.
La versione dei Dati denominata MIXED è nata durante le simulazioni ASN per rispondere ad una esigenza particolare: se l'utente è interessato a vedere i dati più freschi, senza però escludere i riaperti (prendendo quindi il prodotto che era stato validato prima della riapertura).
Tutte queste logiche sono esposte anche in ODS per l’estrazione dei dati dalle viste.
Il secondo filtro chiave a tendina è quello dove si scelgono le "modalità di incrocio con le afferenze dei contributor".
Qui il punto importante è la modalità di acquisizione delle carriere associate alle pubblicazioni.
Ipotizziamo che un ateneo abbia un solo ricercatore "R" e due soli dipartimenti D1 e D2.
"R" nella nostra ipotesi:
- nel 2016 ha pubblicato 5 prodotti e afferiva a D1
- nel 2017 ha pubblicato 2 prodotti afferiva a D2.
Primo caso di modalità di incrocio: Posizione attuale + pubblicazione: associo la pubblicazione alla posizione attuale dell’autore, ossia al ruolo che ricopre nel dipartimento dove lavora oggi. La pubblicazione segue, come fosse il suo patrimonio, l’autore che si sposta durante la sua carriera.
Se quindi estraggo i dati in un’ottica attualizzata, il dipartimento D1 ha 5 prodotti in meno, che sono passati a D2, diventando 7. Questa è l’ottica utilizzata durante la VQR: D2 ha tutte le pubblicazioni di quel ricercatore, anche se le aveva fatte quando era in D1.
2° modalità: ottica storicizzata. D1 ha 5 pubblicazioni e D2 ne ha 2. È l’ottica della Relazione annuale, che vuole vedere cosa i dipartimenti hanno prodotto negli anni.
3° modalità: posizione ad una data fissata. Associo la pubblicazione a dove lavorava l’autore ad una data fissata. Casi di Bandi richiedono questa modalità di incrocio, vogliono cioè fotografare una particolare data e non oggi, ecco perché è diversa da quella attualizzata. Se l'1 gennaio 2016 è la mia data, allora in quest'ottica IRIS attribuisce 7 pubblicazioni a D1 e zero a D2. Il sistema sta solo dicendo di associare il patrimonio del docente ad una data, ma non fa ulteriori ragionamenti legati alla data di pubblicazione. Attenzione! Non ha senso proiettare indietro negli anni, questa possibilità serve solo per proiettare indietro di poco tempo, al massimo di qualche mese. Volendo andare indietro nel tempo, dovrei successivamente filtrare sulla data di pubblicazione, eliminando le pubblicazioni che a quella data non erano ancora state pubblicate.
Consideriamo ora il caso particolare di un Ricercatore che va in pensione: con la posizione ATTUALE escluderei dall’estrazione le pubblicazioni dei pensionati o dei deceduti, che non hanno più alcuna afferenza valida. Come fare a comprendere le pubblicazioni di coloro che non afferiscono più all’ateneo? Si ricorre alla modalità Ultima posizione disponibile: come la posizione attuale, ma comprendendo coloro che non sono più afferenti.
Prese queste due decisioni importanti, si possono mettere ulteriori filtri, per anno, per dipartimento, per tipologia eccetera. Il sistema suggerisce i potenziali risultati durante la digitazione. Si cancella una selezione già fatta cliccando sulla X.
I dati sono visualizzati in forma tabellare, ma si possono essere esportati in numero illimitato, saltando la visualizzazione. Con l’export in fondo alla pagina, invece, si esporta solo la parte visualizzata nella tabella, ma in diversi formati (limite di 20000 risultati per ogni export).
Ordinamento sulle colonne con le freccine.
Accesso completo al sistema: è quello per amministratori. Accesso dipartimentale o di singolo ricercatore per limitare i risultati.